Doubling Down: World’s First 16-λ Single Fiber Bidirectional Link for AI
The computational needs of Artificial Intelligence (AI) have pushed hardware to its absolute limits. One of the most significant bottlenecks in building a massive, scale-up AI system is interconnect I/O—specifically, the number of optical fibers you can connect to a GPU or a switch. Co-Packaged Optics (CPO) has emerged as a leading solution, but it still faces the physical constraint of fiber real estate.
A traditional scale-up AI network needs at least two optical fibers to connect a pair of communicating chips. For example, FR-4 (Far Reach, 4 lanes) uses two fibers (one for each direction) and DR-4 (Direct Reach, 4 lanes) uses a whopping eight fibers (four for each direction). What if you could create the high-bandwidth optical link between the two chips using only one fiber? That’s exactly what the world’s first 16-wavelength (λ) bidirectional (BiDi) single-fiber photonic link achieves. Our breakthrough represents yet another leap in Lightmatter’s 3D CPO that will revolutionize the next generation of AI supercomputers.
A New Architecture for AI Interconnect
At its core, the technology enables a solitary strand of single-mode (SM) fiber to simultaneously transmit and receive data—a significant leap from traditional solutions that require two or more separate SM fibers for a full-duplex link. This is accomplished through a Dense Wavelength Division Multiplexing (DWDM) technique that uses 16 distinct wavelengths of light centered on the 1310 nm band. With each channel operating at 50 Gbps, the link delivers an unprecedented total bandwidth of 800 Gbps per fiber—400 Gbps Tx and 400 Gbps Rx—over a distance of 1km. This BiDi advancement doubles the radix (the number of I/O ports) and bandwidth density as compared to existing CPO solutions without increasing the fiber count.
As shown in Figure 1, the traffic is interleaved so that eight odd-numbered wavelengths (λ1, λ3, …, λ15) carry data in one direction, while eight even-numbered wavelengths (λ2, λ4, …, λ16) carry data in the opposite direction. We use a high-density arrangement that features 400 GHz spacing between channels going the same way and a tight 200 GHz spacing between adjacent transmit and receive channels.
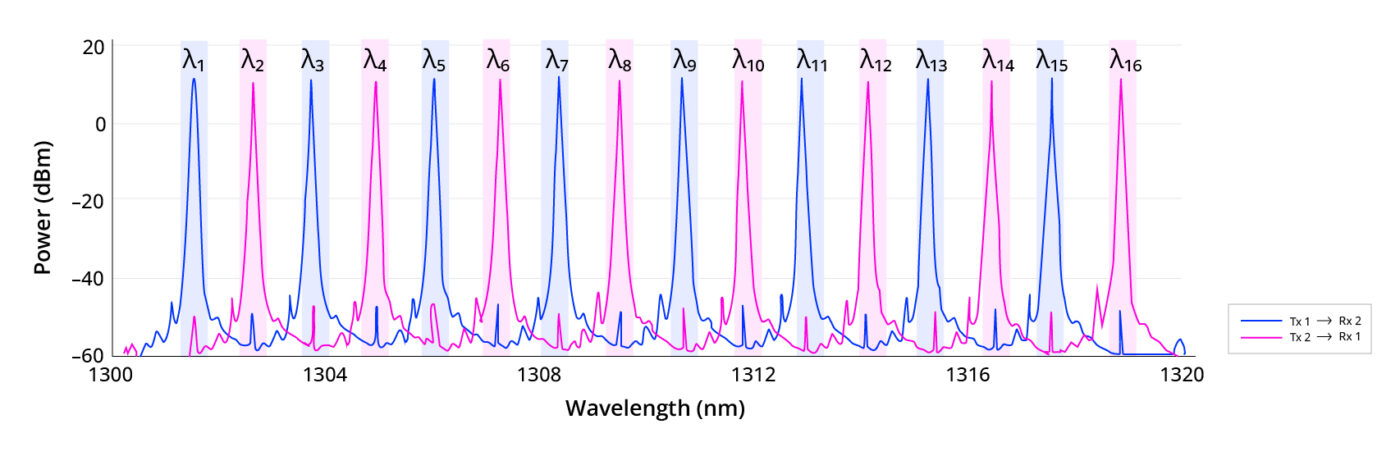
Figure 1: Spectral snapshot of 16 lambda bidirectional optical transmission on the Passage™ platform
Under the Hood: High Performance Silicon Photonics
This leap in performance is made possible by several key innovations integrated onto a single silicon photonics chip. The system uses eight ultra-efficient micro-ring modulators (MRMs) to encode data. The MRM’s compact size is essential for creating compact high-bandwidth photonic integrated circuits (PICs). However, MRMs are notoriously sensitive to temperature. To solve this, we incorporate a closed-loop digital stabilization system that actively compensates for any thermal drift, ensuring a continuous, low-error transmission even as the chip’s junction temperature fluctuates. Our architectural innovations also make our 3D CPO solution inherently polarization-insensitive: a crucial feature for practical deployment, as it maintains stable performance regardless of any physical characteristics of or interactions with the fiber cabling that cause polarization shifts. The photonics (MRMs, photodetectors), all analog front-end circuitry, the Tx drivers, and the Rx transimpedance amplifiers are all fabricated monolithically on a single chip, making our solution directly compatible with off-the-shelf, extra-short-reach SerDes.
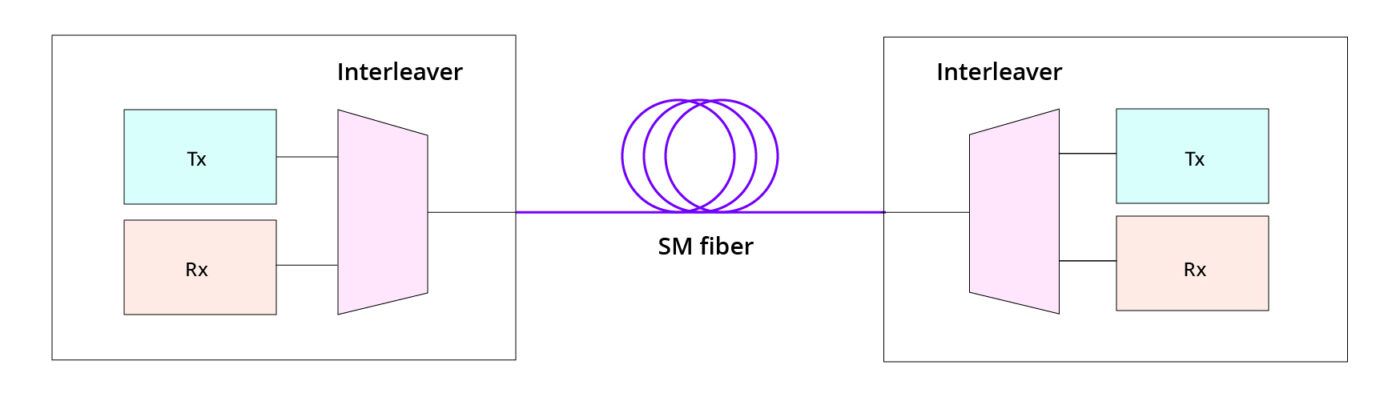
Figure 2: Silicon photonic chip architecture that enables 16λ single-fiber bidirectional communication
Why Radix Matters: Power, Performance, and Cost Savings
Our BiDi technology doubles the radix of a network switch without increasing the number of optical fibers in the network. A higher radix, as illustrated in Figure 3, reduces the number of hops a data packet must take to cross the network. Fewer hops mean fewer switches are needed for a given bisection bandwidth—enabling lower hardware costs and reduced power consumption. Put another way, increased radix (and bandwidth) enables larger, higher performing AI compute clusters without a corresponding increase in the number of switch tiers in their network. A network with fewer switch nodes inherently consumes less power. Finally, fewer hops translate directly into lower end-to-end latency and greater predictability. For tightly-coupled AI training workloads where GPUs are in constant communication, minimizing this latency is paramount for maximizing the overall computational efficiency. Specifically for Mixture-of-Experts (MoE) models, a higher radix allows expert parallel communications to remain within the high-bandwidth domain, preventing them from being bottlenecked by slower scale-out networks. This enables MoE models with a larger number of experts and finer-grained expert configurations, which are crucial for increasing model capacity and achieving faster training times.
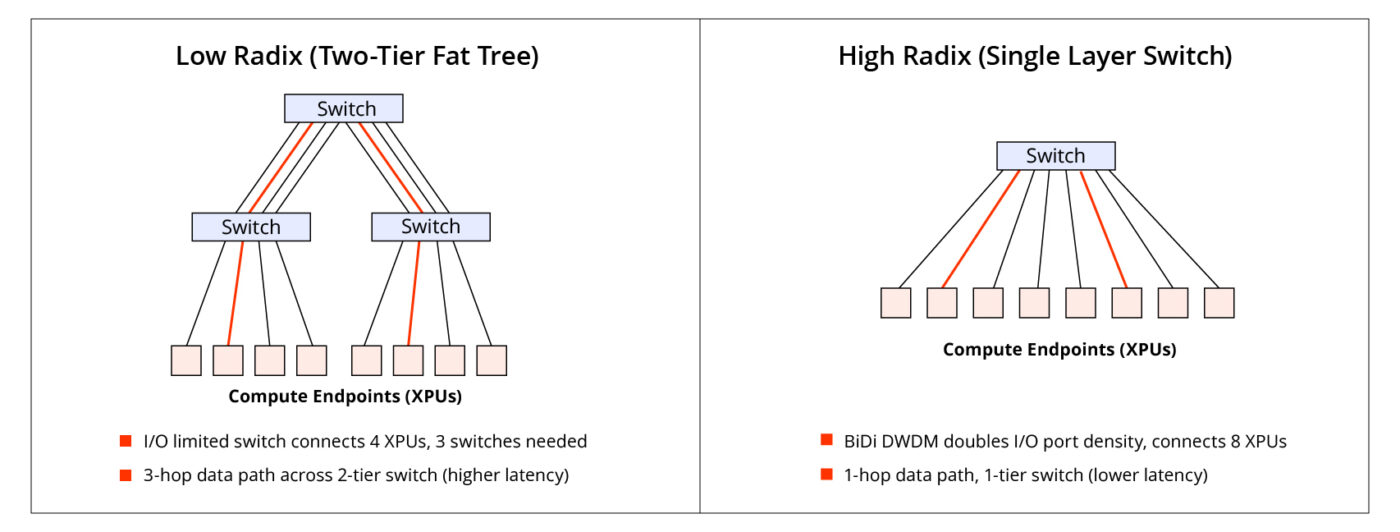
Figure 3: Illustrative impact of radix on data networking complexity and latency
Our BiDi technology provides a direct path to doubling the connectivity of switches and GPUs—enabling the construction of cost-effective, faster, and more power-efficient AI systems. It’s the natural evolution of interconnect for AI.
Darius Bunandar, Ph.D.
Founder and Chief Scientist
Lightmatter and Passage are trademarks of Lightmatter, Inc.